4年前当我第一次接触eucalyptus、EC2,认识云计算的时候就坚定的认为虚拟化技术是未来的趋势。 Image可以快速复制,迁移,部署,这对研发还是运维来说都是十分便利的事情。 尤其是可以在几分钟启动成百上千个instance,服务弹性性能,是多么美好的一件事。 当时XEN、KVM都是业界最前沿的项目。如今虚拟化技术飞速发展,方向已经从Virtual Machine转移到Virtual Container了。 最近基于lxc的docker着实火了,新闻铺天盖地的报道。 下面我们就从docker来了解下Virtual Container。
什么是docker?
docker是为研发和运维搭建的构建、迁移、运行分布式程序的平台,能快速的搭建分布式系统,消除研发,测试和生产环境的差异。 docker包含两大组件:
- docker engine 开源的虚拟化容器平台
- docker hub 分享与管理image的平台
docker engine采用了CS架构,包括
- deamon 运行在主机里,不直接与用户交互,管理和运行container。
- client 接收用户指令,从而构建,分发,运行docker容器。
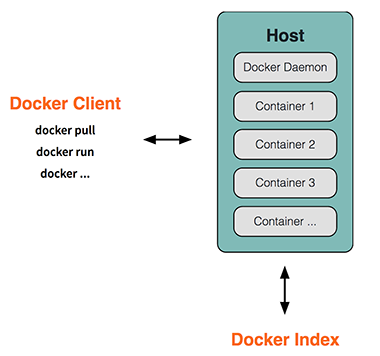
在docker内部,主要由三个模块:
- images 是一个只读模版文件,用来生成containers。docker提供简单的方法可以新建image或者更新已经存在的image。
- containers 是一个目录,包含运行程序的环境。每个containers都是一个隔离安全的程序运行环境。
- registeries 保存image,提供image上传下载的接口。用户可以创建公有或者私有的registeries,公共的registry称为docker hub。
docker的使用模式和eucalyptus、EC2类似。 首先在一台物理机器部署docker engine,从一个初始的container生成一个配置好的image,然后将image上传,保存在docker hub中。 当需要扩容或者迁移的时候,将image拷贝到其他部署了docker engine的物理机器,然后启动container。
Virtual Machine与Virtual Container的区别?
Virtual Machine
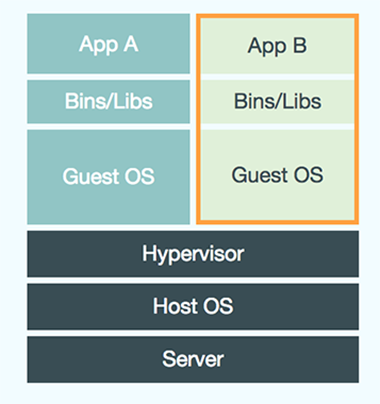
每个instance至少包含数GB,磁盘利用率低。启动instance时,先要启动ghost os,启动耗时较长。优点是完整的环境隔离。
Virtual Container
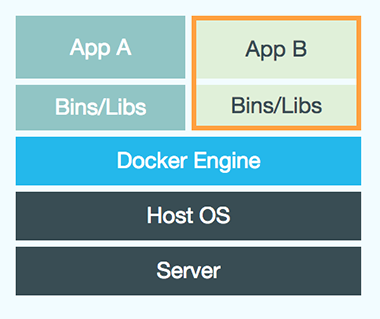
每个container只包含应用程序和它的依赖,运行在隔离的用户态环境中,和其他容器共享操作系统的资源。 因此container不但有VM的资源隔离和分配的优点,而且有更高的效率。
Virtual Container如何实现?
namespace
namespace是轻量级的进程虚拟化。主要的开发人员是 Eric Biederman,第一阶段的用户态namespace已经合入了linux 2.6.23。 从linux 3.8开始,非root权限的进程可以创建自己的用户态namespace,从而获得对应完整的root权限。目前实现了六种namespace,包括:
- mmnt(mount points,filesystems):
- pid (processes)
- net (network stack)
- ipc (System V IPC)
- uts (hostname)
- user(UIDs)
还有4种未实现的namespace
- security
- security keys
- device
- time
每个namespace的目标是包含部分全局的系统资源,在每个进程看来,他们拥有独立的全局资源。 namespace的目标之一就是实现轻量虚拟化的containers,即让一组进程感觉自己就是系统的仅有的进程。
namespace的原理简单,但是实现非常复杂。
首先,进程描述符struct task_struct中增加了一个成员struct nsproxy用来标记进程的namespace
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns;
struct net *net_ns;
}
kernel会根据相应的标记来设置struct nsproxy的值
// include/linux/Sched.h
#define CLONE_NEWNS 0x00020000 /*New namespace group?*/
#define CLONE_NEWUTS 0x04000000 /*New utsname group?*/
#define CLONE_NEWIPC 0x08000000 /*New ipcs*/
#define CLONE_NEWUSER 0x10000000 /*New user namespace*/
#define CLONE_NEWPID 0x20000000 /*New pid namespace*/
#define CLONE_NEWNET 0x40000000 /*New network namespace*/
在内核态,调用do_fork时,clone_flags使进程实体获得不同的namespace
//kernel/Fork.c
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
在用户态,系统调用clone时,带上相应的flags能使进程获得不同的namespace
// man 2 clone
#define _GNU_SOURCE
#include <sched.h>
int clone(int (*fn)(void *), void *child_stack,
int flags, void *arg, ...
/* pid_t *ptid, struct user_desc *tls, pid_t *ctid */);
这样进程启动的时候就获得了相应的namespace。 对于每个namespace的实现,方式各不一样,大致是通过对比相应的资源中namespace来判断此进程是否有该资源的权限。
用户看到的namespace是由一个唯一的inode号标识,在linux 3.8后的版本可以通过ls /proc/< pid >/ns来查看。
cgroup
cgroup提供了聚合和划分进程和他们的子进程到不同等级的进程组里的机制。 cgroup的思想很简单,即划分进程到不同等级的进程组里,然后给这些进程组提供独立的系统资源。 这项目由google的工程师Paul Menage和Rohit Seth发起,现在的维护者是Li Zefan和Tehun Heo。ps.Li Zefan是华为的工程师喔!
相对于namespace的单进程资源隔离,cgroup提供了基于进程组的资源管理。 那么cgroup是不是基于namespace来提供进程组的资源管理呢? 目前还不是,后续会不会更改,还需要继续关注。cgroup的现实是通过在kernel的函数中设置了hook来达到相应的功能。
- 在linux启动(init/main.c)时,运行各种初始化
- 在进程创建
fork和销毁exit时,初始化进程的cgroup信息 - 使用新的文件系统类型 “cgroup”
- 在进程描述符
struct task_struct中添加- struct css_set *cgroups;
- struct list_head cg_list;
- 增加proc系统文件的入口:
- 每一个进程 /proc/< pid >/cgroup
- 系统级 /proc/cgroups
因此我们可以在不支持namespace的kernel中构建cgroup。
从实现来看,cgroup是一种虚拟的文件系统(VFS)。cgroup的信息是随内核存在,当系统重启,所有的cgroup信息将被删除。
LXC
LXC(linux containers)是linux kernel容器特性的用户态接口, 它集成了多个kernel的特性,包括
- namespace
- chroot
- cgroup
- Apparmor and SELinux profiles
- Seccomp policies
- Kernel capabilities
通过这些特性和工具组合,LXC构建一套不需要独立kernel的情况拥有独立的linux运行环境的容器。 这样使得用户可以采用更低的成本来构建一个类似于虚拟机的环境。
总结
docker是基于LXC采用go语言编写的服务。 docker已经构建出类似EC2从构建,迁移,存储,分发的一整套服务。 docker的创始人Solomon Hykes甚至宣称,docker能将互联网升级至下一代。 这里的互联网应该特指云计算。 因为google基础架构部副总裁也说,我们和docker联手,把容器技术打造为所有云应用的基石。 我打开docker的github,发现docker完全由go编写,确实震惊的好一会,我猜想这也是为什么docker能等到google这种大厂商支持的原因之一。 Virtual Container能不能取代Virtual Machine有待观察,仅仅靠docker、google的力量远远不够. 但基于进程的资源隔离比基于内核的资源隔离在粒度级别更低的层级控制资源,发挥物理机器的性能,这一点来说已经有足够的优势。
参考文献
1.linux kernel 3.18
2.linux kernel 2.6.32