当拿到一台刚刚装好系统的机器后,我们需要构建一个相对安全的环境。 许多Linux版本都使用iptables作为默认的防火墙,但是并未做过多的限制。 为了加强机器的安全性,我们需要使用iptables添加一些基本的规则。
Iptables的使用简介
iptables的规则有许多配置项,这些配置项可以组合成各种规则。 每一个网络包经过iptables都会按顺序匹配规则,如果有匹配成功的规则则被过滤或者放行。 本文只需要使用简单的配置项来完成基础的防火墙,这些配置项都非常有用。
-L : 显示当前iptables的规则
-A : 在iptables加入一条规则
-I : 在之前两条规则之间插入一条规则
example: -I INPUT 3 (在规则链中的第三个位置插入一条规则)
-v : 提供一条规则的详细信息
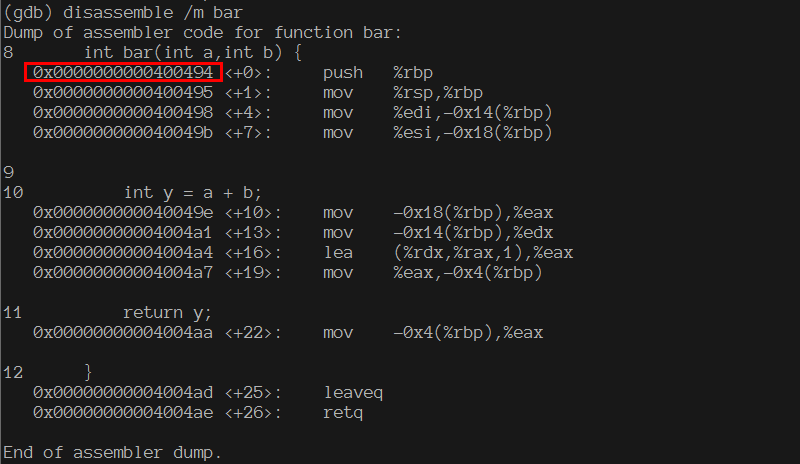
-m conntrack : 基于当前的连接状态设定规则
--cstate : 列出当前连接的状态,连接有四种状态:New、Related、Established、Invalid
-p : 规则对应的网络协议,包括:tcp, udp, udplite, icmp, esp, ah, sctp,或者是all
--dport : 链接的目的端口
-j : 当匹配一条规则时采取的措施,目前有四种操作:
-ACCEPT : 放行
-REJECT : 过滤,并且通知发包者
-DROP : 丢弃,不通知发包者
-LOG : 记录日志,并继续匹配后续规则
添加iptables规则
iptables的使用需要root权限,因此你可以切换为root用户或者使用sudo来获取root权限。
首先查看下iptables当前的规则:
sudo iptables -L
可能会显示出下列信息,每台机器情况各不相同,显示的信息也会有所不同。
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
可能会其他的规则,这时我们可以使用命令来重置iptables让它回到默认的初始状态:
sudo iptables -F
另外,如果你想加快iptables的反应速度,你可以加上命令选项-n。
这个选项会关闭DNS的查找和阻止iptables在规则中反向查找IP信息。
使用的例子:
sudo iptables -L -n
基础防火墙
iptables的初始状态是允许任意进入和发出连接通过,完全没有安全性可言。 因此我们需要先关闭所有的端口,但是不能关闭当前的ssh链接,第一条规则是保持当前的连接状态。
sudo iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
命令解释:
- -A : 在iptables的规则列表后面加入一条规则
- INPUT : 这条规则是input规则链的一部分
- -m conntrack –ctstate ESTABLISHED,RELATED : 是当前链接和与其相关的链接都是允许的。
- -j ACCEPT : 规则匹配后的操作是保持连接
假设服务器上有两个安全的服务ssh和web,即需要开input的22端口和80端口,我们执行下面两条命令:
sudo iptables -A INPUT -p tcp --dport ssh -j ACCEPT
sudo iptables -A INPUT -p tcp --dport 80 -j ACCEPT
命令解释:
- -p : 链接的网络协议类型,上面两个例子中是tcp
- –dport : 链接的目的端口, ssh是默认22,如果修改了ssh的端口,请指定端口号
现在我们可以开始关闭所有不安全连接了。 因为这条规则是列表的最后一条规则,所有的链接都会先匹配前面两条规则,因此不会影响前面的设定。 关闭其他连接的命令:
sudo iptables -P INPUT DROP
现在我们的iptables是这样
sudo iptables -L
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT all -- anywhere anywhere ctstate RELATED,ESTABLISHED
ACCEPT tcp -- anywhere anywhere tcp dpt:ssh
ACCEPT tcp -- anywhere anywhere tcp dpt:http
这样基础防火墙搭建基本完成。 在实际的操作中,我们还要允许服务器的回环访问。 如果直接把规则添加到列表的后面,则会被前一条规则过滤。 现在我们把这条规则添加到列表的第一的位置。
sudo iptables -I INPUT 1 -i lo -j ACCEPT
命令解释:
- -I INPUT 1 : 把这条规则添加到列表第一的位置
- lo : 回环
现在基础防火墙完成!你可以查看iptables的详细信息。
sudo iptables -L -v
显示如下:
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT all -- lo any anywhere anywhere
1289 93442 ACCEPT all -- any any anywhere anywhere ctstate RELATED,ESTABLISHED
2 212 ACCEPT tcp -- any any anywhere anywhere tcp dpt:ssh
0 0 ACCEPT tcp -- any any anywhere anywhere tcp dpt:http
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 157 packets, 25300 bytes)
pkts bytes target prot opt in out source destination
后续你可以根据需要添加更多的规则。
保存iptables的规则
当系统重启后,iptables的规则会清空,因此我们需要保存iptables的规则。
我们可以使用服务iptables-persistent或者是把iptables的规则保存到/etc/iptables/rules.v4文件内。
参考文献
1. <How To Set Up a Firewall Using Iptables on Ubuntu 12.04>